NLP_Text_Stock_Prediction
Predicting Stock Price Movements Using Daily News
Click HERE to see the full and detailed script
Introduction
This was a group project in my NLP class exploring the effectiveness of LSTM networks and BERT embeddings in forecasting next-day stock price movements. We developed a baseline LSTM model using historical stock data and an advanced model combining LSTM and BERT embedding, which leverages daily news headlines. Our findings show a significant improvement in predictive power with the final model, evidenced by increases in the AUC scores.
A key difference from the common sentiment analysis approach is that we are using the embeddings directly to feed into the LSTM, without classifying them as labels of “good”, “bad”, or “neutral”. We believe that by inputing the embeddings rather than multiclass scores to the LSTM, we are providing more information to the LSTM model and give a better predictiveness. So far, we only compared the LSTM baseline with the LSTM with BERT embeddings, but in the future, we will also compare it with LSTM with sentimental analysis.
Objectives
- Establish Baseline Model: Develop a baseline LSTM model using historical stock data.
- Develop Hybrid Model: Combine LSTM with BERT embeddings for analyzing stock data and news headlines. The extracted complex embeddings from news headlines are used for nuanced stock price impact analysis.
- Quantitative Evaluation: Measure improvements in predictive accuracy using AUC and compare the hybrid model against the baseline.
Data Collection
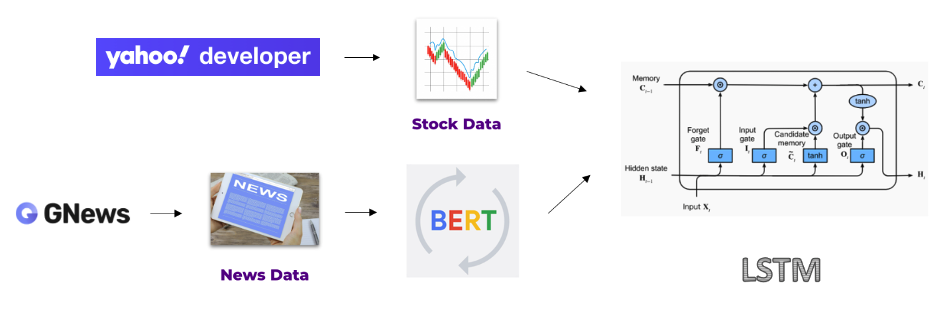
We utilized GNews API for gathering over 100,000 news article headlines related to business and technology, spanning 2020 to 2023. Stock data was sourced from Yahoo Finance API, focusing on S&P 500 companies.
Preprocessing
- Target Labeling: The label for training data was derived from daily stock price movement of S&P 500.
- Daily News Aggregation: We concatenated all headlines from a single day, along with stock price movement labels.
- Handling Exception Cases: The dataset includes adjustments for holidays and market closures.
- Train, Test Split: The train, validation, and test data split was executed using a rolling-window method. During hyperparameter tuning, the optimal rolling-window (lookback period) was found, and this period was then used to construct the final training and test datasets.
Methodology
- LSTM Baseline Model: This model serves as a performance benchmark.
- LSTM with BERT Embeddings: We developed a model that uses BERT embeddings of news headlines combined with LSTM to predict stock prices.
- Tokenization for BERT: Implemented a strategy to handle BERT’s token limitations.
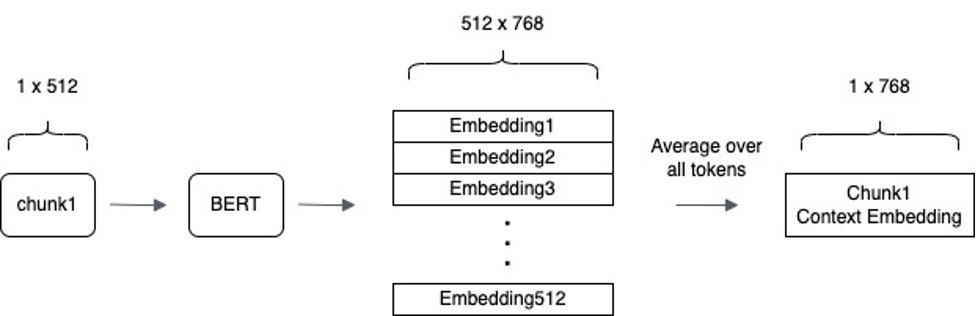
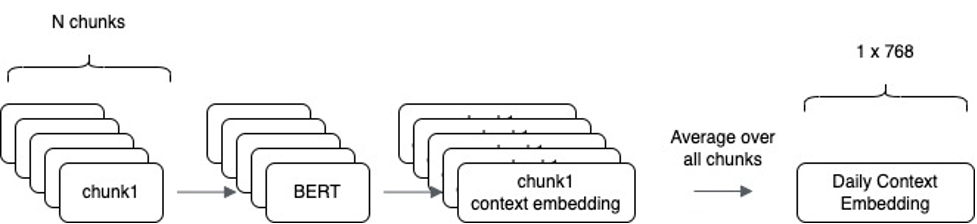
To accommodate the high volume of daily news and BERT model’s token limit, a customized approach was adopted. News headlines were tokenized using BertTokenizer and then segmented into smaller chunks to stay within BERT’s 512 token limit. Each chunk was processed through BERT to generate embeddings, represented as 3D tensors with dimensions reflecting token count and hidden layer nodes. These embeddings were averaged at the token level to create a single context vector per chunk. By iterating this process over all chunks and averaging these embeddings, a unified vector representing the overall context of a day’s news was obtained.
 |
|---|
| Figure 1: This image shows how a single chunk of news headlines with a token size of 512 is transformed into embeddings by the BERT model and averaged. |
 |
|---|
| Figure 2: Representation of Daily Context Embedding. This figure illustrates the aggregation of individual embeddings into a single vector that captures the essence of a day’s news. |
Results
We employed AUC score to evaluate model performances.
| Method | AUC |
|---|---|
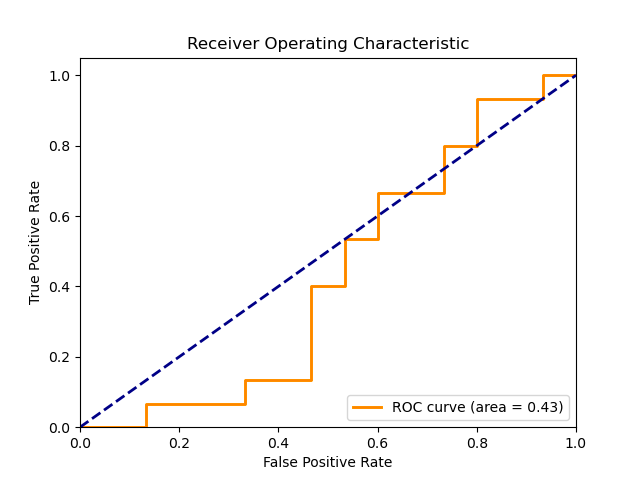
| Baseline LSTM | 0.43 |
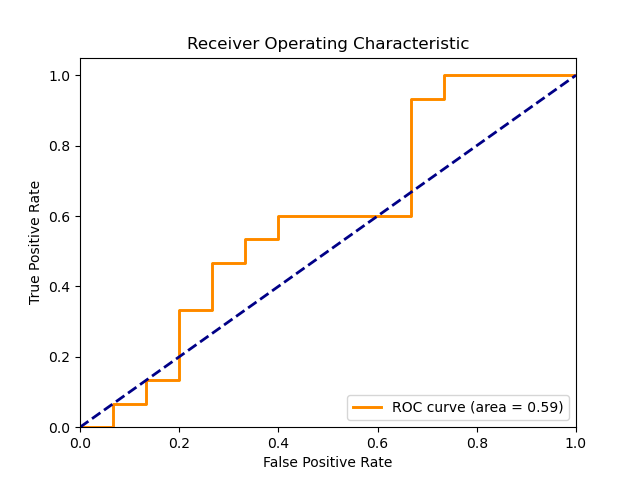
| LSTM + BERT Embeddings | 0.59 |
 |
|---|
| Figure 3: ROC for baseline model |
 |
|---|
| Figure 4: ROC for baseline + BERT model |
We acknowledge that the 0.43 AUC score is peculiar and that our baseline model needs improvements. However, we believe that there is still a value in using this baseline due to the improvement that the BERT Bembedding gives.
Discussion
The LSTM with BERT Embeddings model outperformed the baseline, indicating its effectiveness in stock price movement forecasting. This suggests its general effectiveness, but further analysis is required to test whether the improvement in the AUC is not due to chance.
Conclusion
In this project we explored the potential of utilizing NLP techniques, specifically the BERT model, for financial tasks. Combining news with past price data improved the model’s ability to assess news impact on prices. Further improvements can be made by increasing the dataset (currently limited to 797 trading days) and including financial features like volatility and trading volumes. Also, a direct comparison between our model and a model using sentiment analysis should be conducted to observe the efficacy of using BERT embeddings directly.